一种基于强化学习的云应用弹性伸缩算法
时间:2023-01-15 20:15:06 来源:天一资源网 本文已影响 人 
帅 斌 龙士工
(贵州大学计算机科学与技术学院 贵州 贵阳 550025) (贵州省公共大数据重点实验室 贵州 贵阳 550025)
云计算技术是当前流行的并正在发展的技术,云计算主要有三个市场:基础设施作为服务(IaaS)、平台即服务(PaaS)、软件即服务(SaaS)。云计算的特点之一就是弹性,这使得云用户可以根据自己的业务需求动态地增加或释放计算机资源,并且用户只需要为自己正在使用的资源付费,而正是由于这个特性,吸引着Web应用的服务商把他们的应用移动到云上来。比如网站Groupon就把自己的网站部署到了Amazon EC2(IaaS)和Force.com(PaaS)这两个云服务提供商的云上。
基础设施服务(IaaS)提供商的弹性功能分为两类:提供给用户需要的一类资源(如网络带宽、CPU、存储等)为垂直弹性;
提供实例(虚拟机或容器)为横向弹性。因此有效地利用云的弹性功能,能够自动和及时地提供和释放云资源是至关重要的。如果提供的资源过多,那么会造成资源闲置形成资源浪费,同时需要支付的成本也增加了。然而如果提供的资源过少,会使得应用的性能下降,响应时间变长,造成用户服务协议(SLA)违约。这种使得云用户能够有最少的管理,同云服务提供商有最少的交互就能实现动态地增加或释放资源,并且能满足用户服务质量(QoS)的是弹性伸缩技术[1]。
现在云计算中能实现弹性伸缩的方法有多种,其中比较传统的是基于阈值的方法,该方法主要通过提前设定好阈值来调整云资源,如文献[2-4]。另一种实现弹性伸缩的是基于时间序列分析的方法,如文献[5]中通过自回归预测与指数平滑和前馈(BP)人工神经网络提出了一个基于需求预测的云计算弹性伸缩策略,文献[6]提出了一个基于指数平滑法的预测模型,文献[7]中以差分自回归移动平均模型进行负载预测。文献[8]以时间序列分析与阈值的混合方法提出一个预测模型。
强化学习相对阈值与时间序列分析的优点是当负载规律变化时能动态地调整策略,重新在环境中学习达到最优策略。文献[9-11]提出使用Q-学习算法实现弹性伸缩,文献[12]对SaaS云服务提供商的弹性伸缩策略使用了Q-学习算法,文献[13-14]对数据流处理应用实现弹性提出有模型的强化学习,文献[15]通过减少状态集使Q-学习算法更快达到收敛。
仅有少部分研究Q-学习算法的收敛问题,如文献[14-15]。此外,几乎所有研究使用的都是单步更新的Q-学习算法[9-15],缺少多步更新算法的优势。
因此本文对IaaS云服务提供商上Web应用的弹性问题进行了研究建模,提出一种基于强化学习的弹性伸缩算法PDS-lambda。该算法只学习动态未知的信息,同时采用多步更新,旨在使算法更快收敛到最优策略,最后通过仿真实验同文献[15]的Q-学习算法和文献[14]的PDS单步更新算法的性能进行了对比。
1.1 架构设计
为了及时和自动地增加或减少虚拟机(VM),来应对Web应用迅速变化的负载,本文对Web应用的弹性伸缩策略如图1所示。

图1 云资源弹性伸缩架构
负载均衡器是Web应用的入口,它接收所有用户的请求,将其分配到已安装Web应用程序的VM上,然后将响应发送回用户。当管理服务器增加或减少VM时,负载均衡器还必须更新VM表,并调整负载平衡策略。
管理服务器包括监视系统和云资源管理系统。监视系统持续监视Web应用的用户请求,收集用户服务协议(SLA)违约和虚拟机使用信息。云资源管理系统在每个时间段对监视系统得到的信息进行算法分析,根据算法结果对IaaS云服务提供商进行租赁,采取合适的弹性扩张操作或直接采取弹性收缩操作来调整其拥有的VM数量,并将改变后的VM表发送给负载均衡器。本文把以上过程模型化为马尔可夫决策过程(MDP)。
1.2 MDP
定义1MDP为6元组〈S,A,P,R,α,β〉,S表示有限状态集,A(s)为每个状态s的有限动作集,P(s′|s,a)为在状态s选择动作a∈A(s)转移到状态s′的概率,R(s,a)为在状态s采取动作a的成本,α∈[0,1]是学习率,β∈[0,1]是未来成本的折扣因子。

在状态st=(1,wt)时,动作集为A(s)∈(0,+1);
状态st=(Umax,wt)时,动作集为A(s)∈(0,-1);
除此之外每个状态s的动作集为A(s)∈(+1,0,-1)。Web应用在时刻t开始时选择动作+1、0、-1分别代表增加虚拟机、不改变、减少虚拟机。
由于状态中的HTTP请求到达速度无法确定,因此在状态s下采取动作a后转移到状态s′的状态转移概率与HTTP请求到达速度有关,因此P(s|s′,a):

(1)
对每个状态-动作对的成本R(s,a)的评估,从三个方面来进行考虑:
1) 运行虚拟机的成本,运行u+a个虚拟机的总成本为cVM(s,a),运行每个VM的成本为rVM,则运行u+a个虚拟机的成本为cVM(s,a)=(u+a)rVM。
2) 重新配置成本,无论什么时候进行弹性扩张或弹性收缩操作时,Web应用都会经历一个十分短暂的停机的时间,这段时间不会处理请求,尽管这段时间会非常小,但对于一个稳定的应用来说这仍然不可忽视。把动作-1、+1成本考虑为一个常量rRC。
3) SLA违约成本,请求的响应时间超过SLA违约的时间阈值TSLA时,会获得一个SLA违约成本,考虑该成本为一个常量rSLA。
对上述三个成本进行归一化处理后使用简单加权和法,获得状态-动作对的成本R(s,a)为:
WSLA1{T(u,w)>TSLA}
(2)
式中:WVM+WRC+WSLA=1,代表上述三个成本的权重值其和为1。1{a≠0}表示当采取动作a=0时取值为0,而当采取动作a=+1,-1时取值为1;
1{T(u,w)>TSLA}表示当没有产生SLA违约时取值为0,而当有SLA违约时取值为1。
MDP是算法与Web应用之间通过动作a、状态s、和成本R相互循环作用的过程。图2展示了MDP空间过程,在时刻t,算法从Web应用得到状态st与成本Rt,作出决策动作at,在t+1时刻Web应用反馈给算法新的状态st+1,和成本Rt+1。
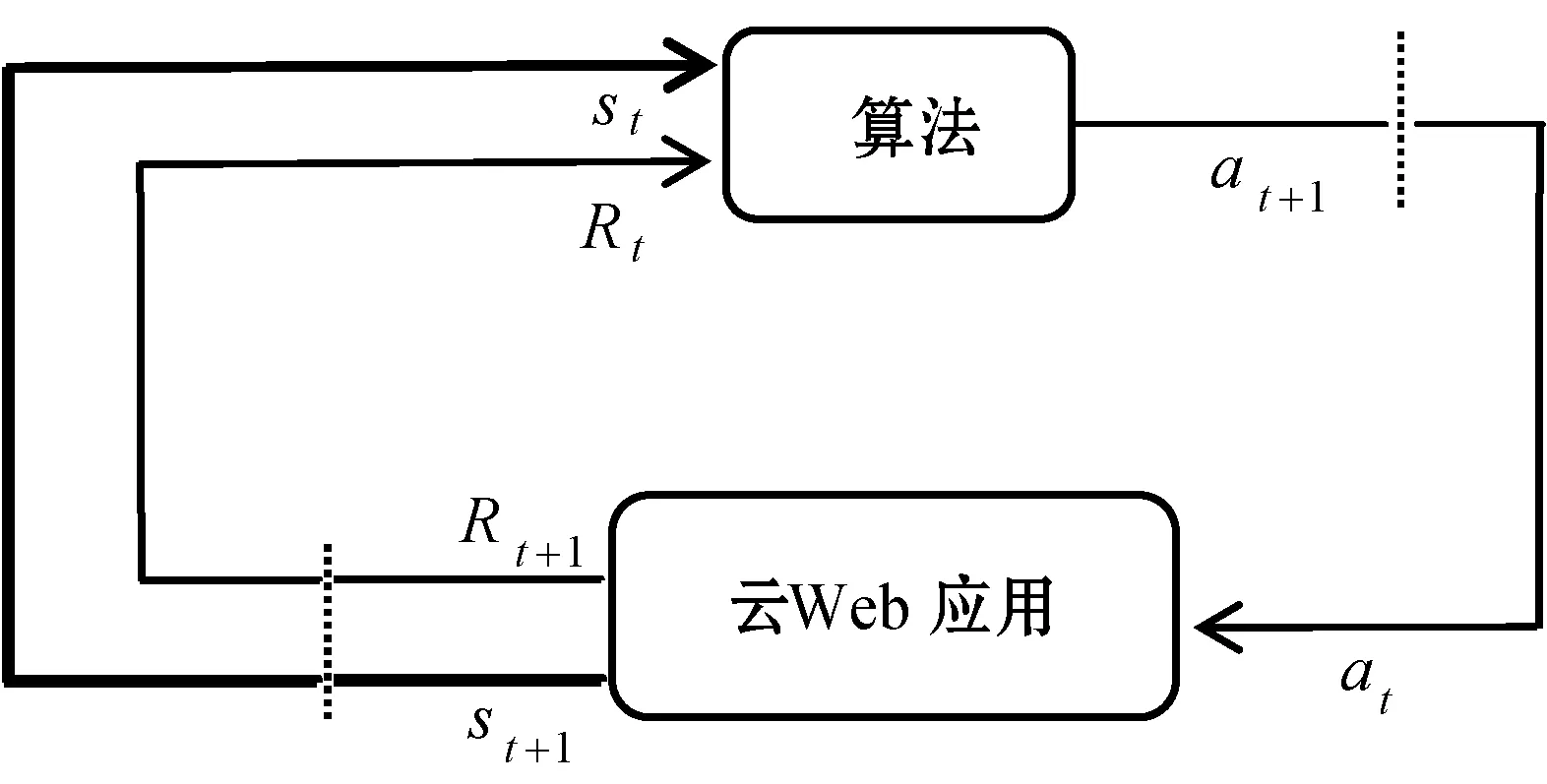
图2 MDP空间过程
图3展示了MDP的时间过程,随着时间增加,状态也随之不断变化,时间越长状态越多算法学习到的信息越多。

图3 MDP时间过程
算法是MDP的核心,这一部分将着重介绍本文提出的PDS-lambda算法。由式(1)知模型中状态转移概率并不确定,与请求到达速度变化有关,而请求到达速度的变化是完全随机的过程,强化学习中的时序差分(TD)算法的思想能解决状态转移概率不确定的问题,TD算法需要在环境中不断采取动作然后观测状态-动作产生的成本,来更新状态-动作值函数Q(s,a)。
TD中典型的Q-学习算法需要不断维护一个Q表,在每个时刻采取相应的动作a,在Q-学习算法中选取动作a的方法是γ-贪婪策略即以1-γ的概率随机选取一个动作,以γ的概率选取最优的Q(s,a)值,然后观察状态-动作对产生的回报R(s,a)来对Q表进行更新。对Q表的更新公式如下:
Q(s,a)←Q(s,a)+α[R(s,a)+

(3)
本文中PDS-lambda算法是在TD算法的思想上建立的,PDS-lambda算法同TD算法一样需要不断维护一个具有状态-动作值函数Q(s,a)的Q表,但本文算法同TD算法的不同之处在于对Q表的更新方法不同,其次本文算法的学习策略即在每个时刻选取动作a的方法也不同。
PDS-lambda算法将由下面两个部分进行描述,第一部分引入了PDS实现对Q表更新方法的第一次改进,并且介绍了本算法的学习策略;
第二部分引入多步更新的思想在PDS的基础上实现对Q表更新方法的第二次改进。
2.1 PDS与学习策略
PDS-lambda算法在每个时刻t的末尾根据上一个状态st=(ut,wt)采取动作a∈A(st)后转移到下一个状态st+1=(ut+1,wt+1)。但状态的转移过程是需要时间的,不能立刻观测到,其中Web应用在状态st+1的虚拟机数量ut+1可以根据采取的动作a直接获得,而请求到达速度wt+1是无法预知的,只有时刻t+1快结束时才能获得它的值。因此本文的算法在状态st和状态st+1之间引入了决策后状态(PDS),来改变对Q表的更新方式。



图4 当前状态与PDS和下一状态关系
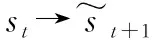
(4)

(5)
(6)
(7)
PDS-Lambda算法的学习策略决定了在每个时刻对当前状态应该选取哪个动作。HTTP请求到达速度并不会因采取的动作不同而改变,因此PDS-Lambda算法只需要学习HTTP请求到达速度这个未知动态信息,不需要随机探索的动作,在学习阶段中该算法采取的学习策略只需不断选取最优。算法的学习策略π(s)如下:

(8)
式(8)表示在每个状态下选取有最小Q函数值的动作。
2.2 多步更新
(9)
式(9)表示在当前时刻的状态与遍历表所得的状态不同时,便进行衰减,而当前时刻的状态与遍历表得到的状态相同时便进行一次标记。由式(7)可得TD误差δ为:
(10)

(11)
PDS-Lambda算法的伪代码如算法1所示。
算法1PDS-Lambda算法
输入 起始状态-s0折扣因子-β
学习率-α衰减因子-λ
2.s=s0;
//初始化状态
3. fort=1,2,3,... do
//每个时刻进行学习
4.a=π(s);
//式(8)

//式(10)

//式(9)
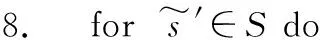

//式(11)

//式(9)
11. end for
12. forai∈A(s) do
//式(6)
14. end for
15.s←s′;
//转换状态
16. end for

3.1 实验设置
实验采用云平台模拟软件cloudsim[16]进行仿真,从而对算法的性能进行评估。在这个部分对Q-学习算法[15]、PDS单步更新算法[14]、PDS-lambda多步更新算法进行仿真。实验环境如下,用cloudsim模拟器创建一个有20台主机的数据中心,一个代理(broker),在这里broker可以模拟为Web应用,在开始时broker拥有5个VM,每个VM的CPU(MIPS)为1 000。


图5 负载变化趋势
设置SLA的违约时间为10 s,请求的最大响应时间超过这个值时就会导致一个处罚。设置学习率α=0.6,折扣因子β=0.8,衰减系数λ=0.8,实例成本、重新配置成本和SLA违约成本的权重各为:
WVM=2/5,Wrc=1/5,WSLA=2/5
本文使用平均成本(average cost,AC)来评估算法的收敛快慢,其数值越快达到最小,收敛速度越快,越节约成本,t为时刻且{t≥1|t∈N},平均成本计算如下:
(12)
3.2 算法复杂度分析


表1 算法时间与空间复杂度
3.3 算法评估
对三个算法所用虚拟机平均数量、重新配置次数、SLA违约次数的分析结果如表2所示。结果反映三个算法使用的虚拟机平均数量相差不大,但使用PDS后算法在SLA违约和重新配置次数上面有非常明显的减少,而PDS-Lambda算法相比PDS单步更新算法使用了多步更新能最快达到收敛形成最优策略从而有最少的SLA违约次数和重新配置次数。

表2 算法性能比较
图6展示了实验中的Q-学习算法、单步更新PDS算法和PDS-Lambda算法的平均成本,可以看到随着时间的变化PDS-Lambda算法表现出了一个最快的收敛,能最快地到达稳定的平均成本。并且从最后稳定状态上来看,PDS-Lambda算法和单步更新PDS算法都能实现比Q-学习算法更低平均成本。

图6 平均成本变化趋势
多数使用强化学习的弹性伸缩算法都没有研究算法的收敛时间。本文针对IaaS云服务提供商上Web应用,提出一种基于强化学习的PDS-lambda算法,该算法用来实现自动控制虚拟机资源的弹性扩张和弹性收缩,使部署在IaaS云服务提供商上的云Web应用有更好的可靠性、适应性和自动性,通过加快收敛让其满足服务质量同时尽可能节约成本。强化学习的方法中存在的普遍问题是算法在收敛到最优策略的过程中时会有一个比较差的性能表现,因此要尽量减少这部分收敛时间来提高算法性能,实验结果表明,该算法利用PDS与多步更新的方法能比已经有的强化学习算法更快达到收敛,节约成本。在未来的工作之中,希望将该算法进一步应用在一个真实的云环境Web应用之中,来评估其实现弹性伸缩时的性能表现。
猜你喜欢 服务提供商弹性学习策略 为什么橡胶有弹性?军事文摘·科学少年(2021年9期)2021-10-13基于分治法的Kubernetes弹性伸缩策略科技研究·理论版(2021年20期)2021-04-20论品牌出海服务型跨境电商运营模式中国经贸导刊(2020年2期)2020-06-01最新调查:约三成云服务提供商正迅速改变其业务模式计算机世界(2018年36期)2018-10-15高效重塑肌肤弹性中国化妆品(2017年12期)2017-06-27网络非中立下内容提供商与服务提供商合作策略研究软科学(2017年3期)2017-03-31Exploration of Learning Strategies from the Study on Language Acquisition Process东方教育(2016年6期)2017-01-16AdvancedTeachingStrategiesofCollegeEnglishVocabulary校园英语·下旬(2016年4期)2016-05-09学习策略在化学教学中的运用研究江苏教育·中学教学版(2014年3期)2014-04-10正手击球弹性动作解析(三)网球俱乐部(2009年13期)2009-11-23 相关关键词: 伸缩玩具美术教案 伸缩 伸缩门 伸缩门采购合同 电动伸缩门采购合同








